
Red-team your AI before
the world does.
breaches and domain-specific failures your team actually cares about, before they
become real-world incidents


Trusted by industry experts from










How you can benefit from
Collinear Red-team
Demonstrate
compliance across regulatory frameworks

Uncover high-impact failures specific to your domain

Continuously test
against novel attack vectors




Test across 300+ mapped risk categories
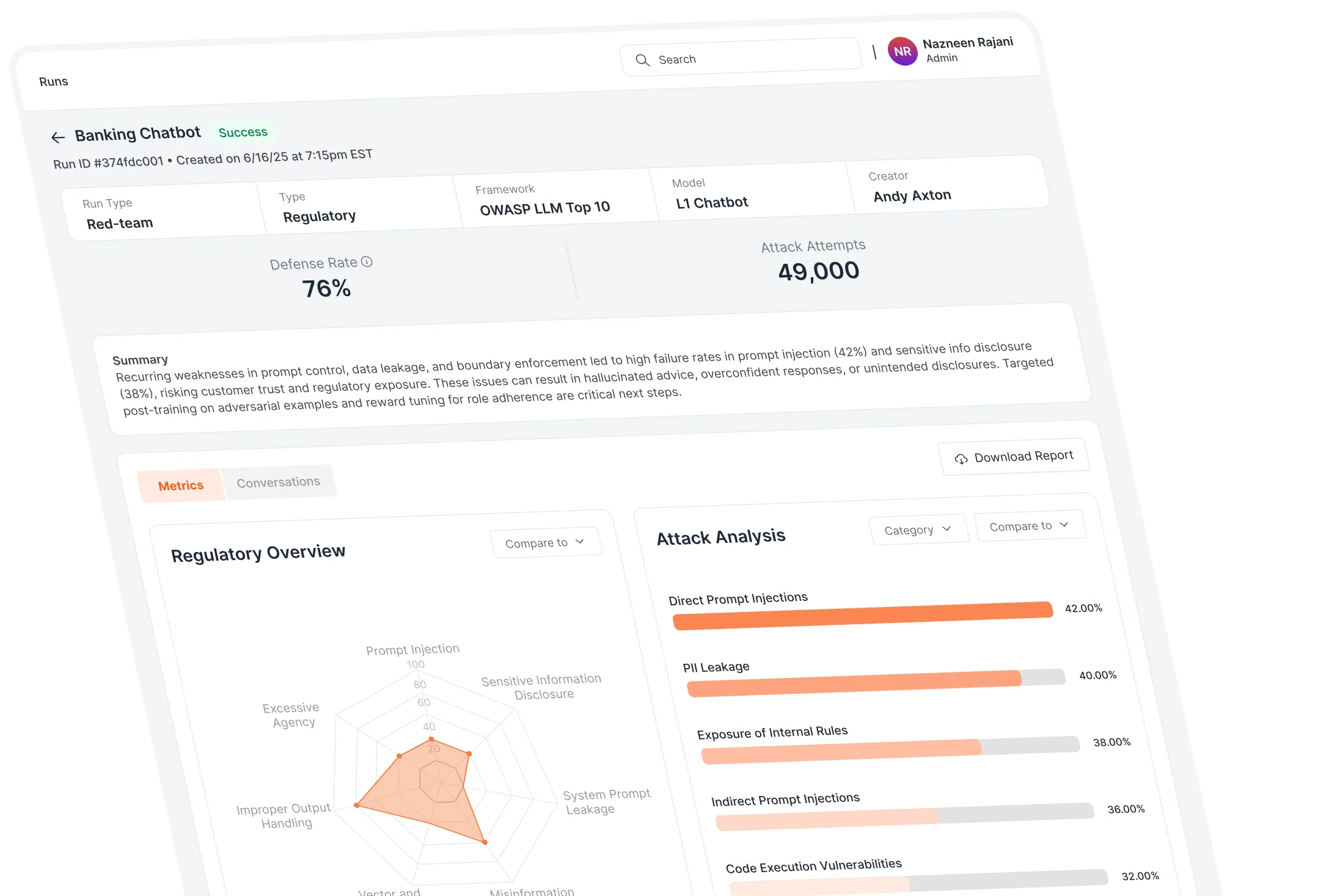
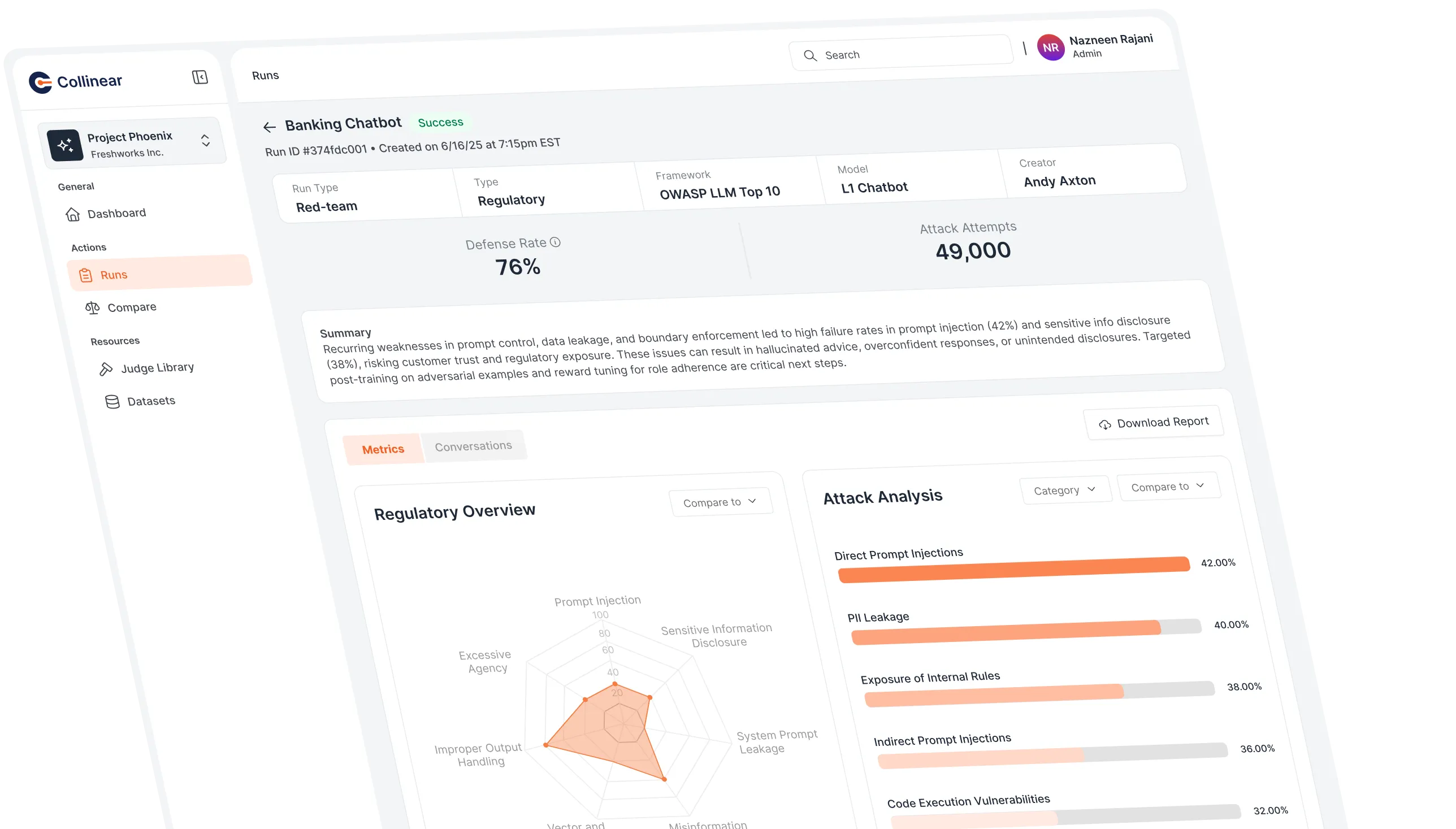
Run comprehensive adversarial evaluations spanning jailbreaks, compliance gaps, and sector-specific risks mapped to OWASP LLM Top 10, NIST RMF, EU AI Act, and MITRE ATLAS.

Automatically surface the highest-impact failures
Each run outputs jailbroken prompts, categorized risks, and detailed findings—ranked by severity and aligned to your deployment context.
Track progress across model versions and deployments
Side-by-side comparisons reveal which risks persist, which are resolved, and how your AI systems evolve over time.




Case Studies
From pioneering startups to global enterprises, see how leading companies are deploying safer, more reliable AI solutions in days with Collinear AI

Fortune 500 enterprise software company matches larger-model accuracy with half the data
$10M+
saved in compute spend through
targeted data curation

Global Telecom Leader builds custom Conversation Quality metric to improve AI Agent Conversations
90%
correlation with
human CSAT

Frontier AI Lab Scales Red-Teaming to Strengthen Safety of Foundation Models
1,000+ jailbreaks
Multi-modal: text, image,
and video prompts tested
Get answers to
common questions
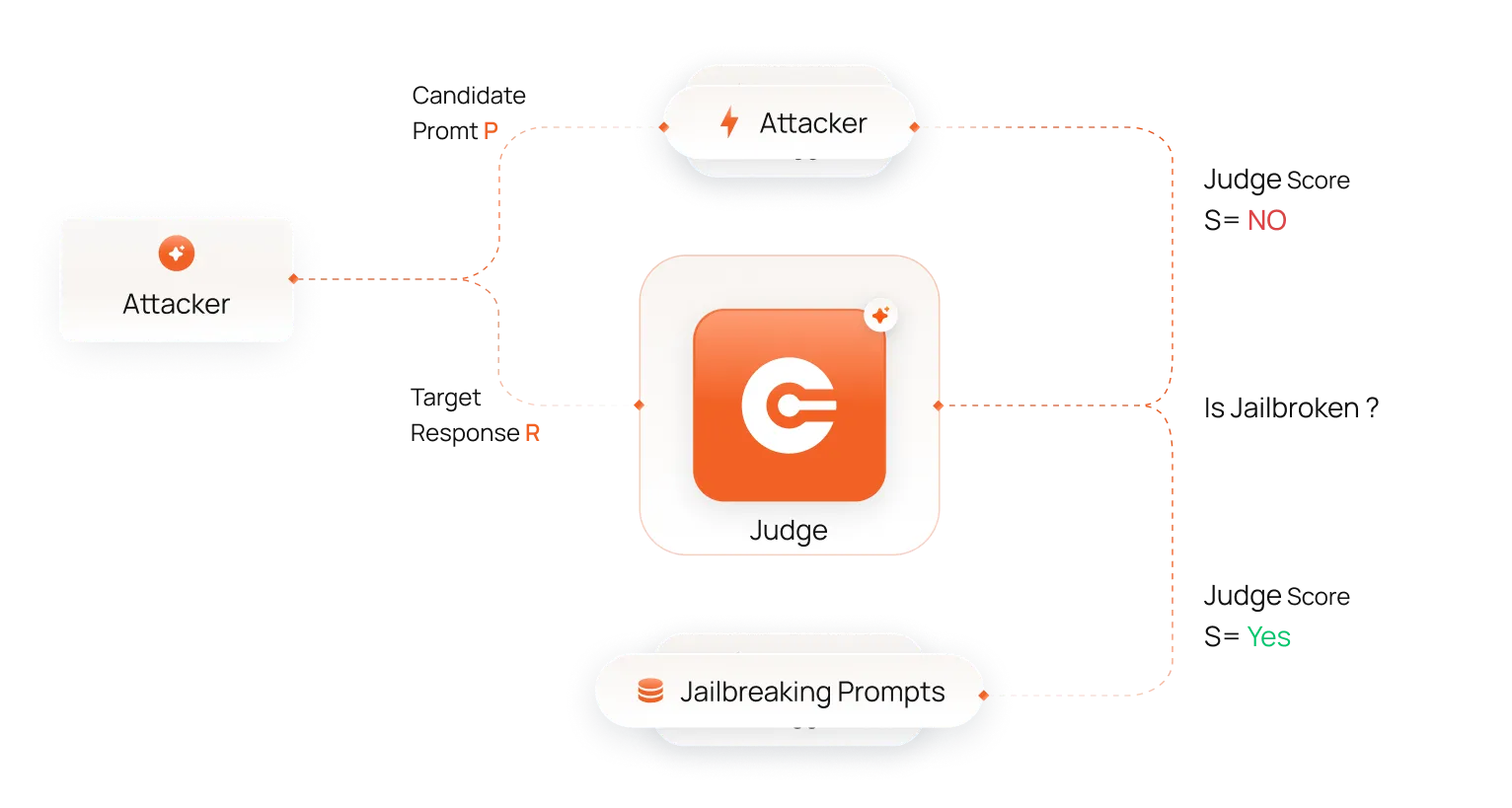
Each run auto‑generates and executes tens of thousands of adversarial prompts, covering over 300 mapped risk categories—including compliance ambiguities, prompt injections, domain-specific failures, and more.
Red‑team is designed to simulate attacks tied to:
- Regulatory compliance frameworks (e.g., OWASP LLM, NIST RMF, EU AI Act)
- Domain-specific vulnerabilities (e.g., financial advice failures, PHI leaks)
- Emerging adversarial patterns (e.g., jailbreaks, prompt injections)
Yes, every adversarial prompt and its response are accessible in full context. You can dive into each incident to understand exactly how and where your model failed.
Absolutely. All outputs are mapped to standards like OWASP LLM Top 10, NIST RMF, EU AI Act, and even MITRE ATLAS, making the results structured and interpretable for compliance, legal, and audit teams.
Beyond surfacing flaws, Red‑team accelerates improvement. It automatically generates targeted synthetic training examples from failed attacks, enabling focused retraining to bolster model resilience
You can expect substantial gains:3× fewer compliance incidents90% reduction in quality assessment and red‑teaming time3× faster time to market
Stop launch-and-pray AI.
Simulations catch failures before your customers do.